GLM-OCR – 智谱开源的轻量级多模态OCR模型,仅 0.9B 参数智谱正式发布并开源 GLM-OCR。据介绍,该模型仅 0.9B 参数规模,支持 vLLM、SGLang 和 Ollama 部署,模型基于GLM-V架构,集成自研CogViT视觉编码器与轻量跨模态连接层...发现资讯2个月前06300
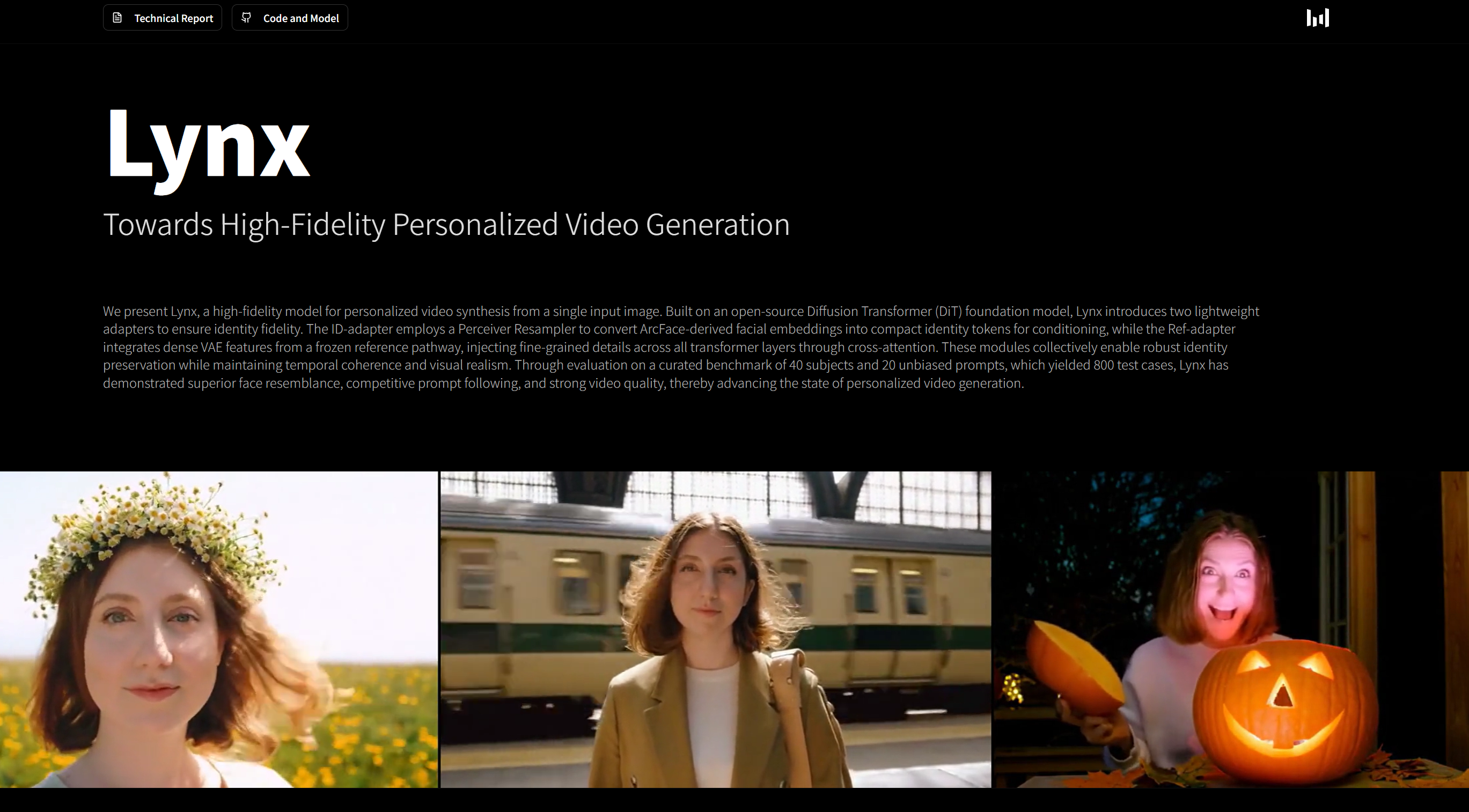
Lynx : 字节跳动推出的高保真个性化视频生成模型,仅需一张人物照片Lynx是字节跳动推出的高保真个性化视频生成模型,仅需输入一张人像照片,即可生成身份高度一致的动态视频。该模型通过单张人物图像即可生成身份一致、动作自然、场景多样的动态视频,在身份保真度、动作连贯性...发现资讯8个月前06270
万相2.6 – 阿里通义推出的新一代视频生成系列模型,首个支持角色扮演模型阿里通义推出万相2.6系列模型,支持音画同步、多镜头生成及声音驱动等功能。旨在实现生成视频在画面与声音上的整体一致性。其分镜控制功能可依据语义理解,将原始素材构建为包含多镜头切换的专业叙事段落。该版本...发现资讯6个月前06240
GPT-5.2 – OpenAI最新推出的通用AI模型系列,能高效处理长文档,支持端到端工作流OpenAI正式推出其迄今最强模型GPT-5.2,专为专业工作和复杂任务设计。在通用智能、长文本处理、智能体工具调用和视觉等方面得到显著提升。在制作电子表格、制作演示文稿、图像感知、编写代码以及理解长...发现资讯6个月前06210
Qwen3-Omni – 阿里通义开源的原生端到端全模态大模型,支持119种文本语言交互Qwen3-Omni模型的发布,标志着开源多模态人工智能领域的一个重要里程碑。该报告旨在对Qwen3-Omni进行全面深入的技术剖析,通过先进的深度学习技术,输入的视频、音频、文本直接进入核心模型,中...发现资讯9个月前06210
SSVAE – 智谱AI开源的频谱结构化变分自编码器,提供快速生成视频的能力ssvae(spectral-structured vae)是智谱ai研发的一种面向视频生成任务优化的新型变分自编码器。SSVAE 在相同生成质量下,收敛速度提升3倍,仅用1.3B参数量就超越了4B参...发现资讯6个月前06180
PixVerse V5.5 – 爱诗科技推出的视频生成大模型,支持音频和视频同步生成PixVerse V5.5是爱诗科技推出的最新一代AI视频生成大模型,模型基于自研的多模态视觉语言(MVL)架构,采用Diffusion与Transformer混合设计,支持音画同步生成,简化从构思到...发现资讯6个月前06150
商汤开源的首个实时视频生成推理框架–LightX2V ,支持多种视频生成任务商汤开源了行业首个能实现实时视频生成的推理框架LightX2V,支持低资源部署,通过DiT蒸馏加速、轻量化 VAE、稀疏注意力等优化,实现低成本、强实时的视频生成。框架支持多种硬件部署,提供 Grad...发现资讯6个月前06120
LongCat-Flash-Omni – 美团开源的实时交互全模态大模型,支持文本、语音、图像和视频的多模态输入与输出美团正式发布LongCat-Flash-Omni,业界首个实现全模态覆盖、端到端架构、大参数量高效推理于一体的开源大语言模型。,LongCat-Flash-Omni 在全模态基准测试中达到开源最先进水...发现资讯7个月前06090
GLM-4.6V – 智谱开源的多模态大模型系列,支持云端、本地及多种硬件环境部署智谱正式上线并开源 GLM-4.6V 系列多模态大模型,该模型支持高达 128k tokens 的超长上下文,在视觉理解精度方面处于同规模模型的领先梯队,并首次将工具调用能力深度原生集成至视觉架构中...发现资讯6个月前06070