
排序

Gemini Deep Research – 谷歌推出的深度研究Agent,能深入复杂信息环境中获取精准数据
谷歌推出Gemini Deep Research深度研究智能体,基于Gemini 3 Pro构建,专为长周期内容收集与综合任务优化打造,其幻觉率较此前模型降低40%,是谷歌迄今“最具事实性”的智能模型...

Piktochart – AI设计工具,支持通过文字输入快速生成多种视觉内容
Piktochart 是一款专注于信息图表设计的在线平台,专为快速创建视觉内容设计。旨在帮助用户轻松创建信息图表、报告、演示文稿、海报、传单等视觉内容。Piktochart 提供丰富的模板和资源,适合...
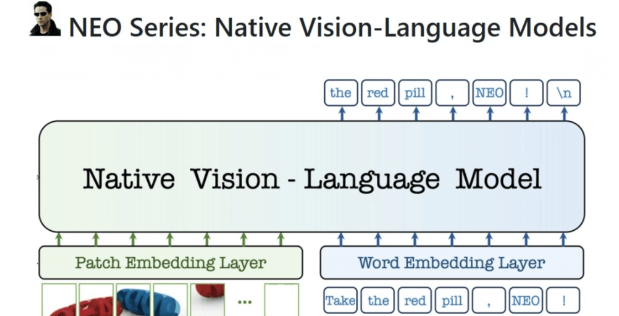
NEO – 商汤联合南洋理工开源的全新多模态模型架构,训练仅需1/10数据量,达到顶尖的视觉感知能力
商汤科技联合南洋理工大学S-Lab发布并开源全新多模态模型架构NEO。该架构号称是行业首个实现深层次融合的原生视觉语言模型,通过原生图块嵌入、三维旋转位置编码和多头注意力机制创新,实现视觉与语言在底层...

Claude-Mem – 开源Claude Code记忆插件,开启长期记忆功能
Claude-Mem是一款智能插件,旨在为 Claude AI 提供长期记忆功能。该插件能够自动捕获在编码会话期间Claude的所有操作,通过AI进行压缩,并将相关的上下文信息注入未来的会话中,实现持...

Qwen3-VL Cookbooks – 阿里推出的多模态任务开发指南,支持多种应用场景
Qwen3-VL Cookbook是一份为开发者准备的多模态实践指南,涵盖从文档解析到视频理解的各类应用场景。核心能力包括万物识别、文档解析、OCR+关键信息提取、视频理解、智能体控制和空间理解3D定...

DeepSearchQA – 谷歌开源的AI研究Agent测试基准,精准衡量智能体在真实研究场景中的综合能力
谷歌开源全新网络研究智能体基准DeepSearchQA,成为AI界对抗GPT-5.2的爆款工具。涵盖17个领域的900项人工设计的因果链任务,其中每个步骤都依赖于先前的分析。首次引入过程性评估指标,通...

GWM-1 – Runway推出的首个通用世界模型,实时生成和模拟虚拟世界
Runway推出首个通用世界模型GWM-1,采用自回归式建模方式,按帧顺序预测视频内容,具备实时响应与交互能力。其核心理念在于让AI系统在内部构建一套对现实世界运行机制的完整模拟。这就好比让计算机拥有...

Kaleido – 智谱AI开源的多主体视频生成框架,支持多张参考图像和文本提示进行视频生成
智谱开源团队联合合肥工业大学和清华大学提出了一种名为Kaleido的开源多主体参考视频生成框架,旨在解决现有开源S2V模型在多主体场景中保持一致性及背景解耦的难题。利用深度学习和计算机视觉技术,能够生...

DeepSeek-Math-V2 – DeepSeek开源的数学推理模型,能实现自我验证和修正推理过程
DeepSeek上线全新数学专用模型DeepSeekMath-V2,该模型基于DeepSeek-V3.2-Exp-Base构建,参数规模达685B。它最大的亮点是能像数学家一样自我验证和修正推理过程...