SpikingBrain-1.0 – 中国科学院推出的类脑脉冲大模型,能实现数量级的效率提升近日,中国科学院自动化研究所科研团队成功研发出首款类脑脉冲大模型SpikingBrain-1.0。SpikingBrain-1.0在多个性能方面实现突破:实现极低数据量高效训练、实现推理效率数量级提升...发现资讯9个月前06500
Qwen3-Omni-Flash – 阿里通义推出的全模态大模型,支持119种文本语言、19种语音识别语言和10种语音合成语言qwen3-omni-flash(qwen3-omni-flash-2025-12-01)是阿里巴巴qwen团队全新发布的全模态大语言模型。可实现文本、图像、音频和视频的无缝输入与同步输出。模型支持1...发现资讯6个月前06480
Anthropic最新推出的AI编程模型–Claude Sonnet 4.5 ,能专注工作超 30 小时Anthropic 公司推出了一款名为 Claude Sonnet 4.5 的新一代前沿模型,该模型在编码、计算机操作及满足实际业务需求方面能力更强,同时在网络安全、金融、科研等专业领域表现突出。 C...发现资讯8个月前06450
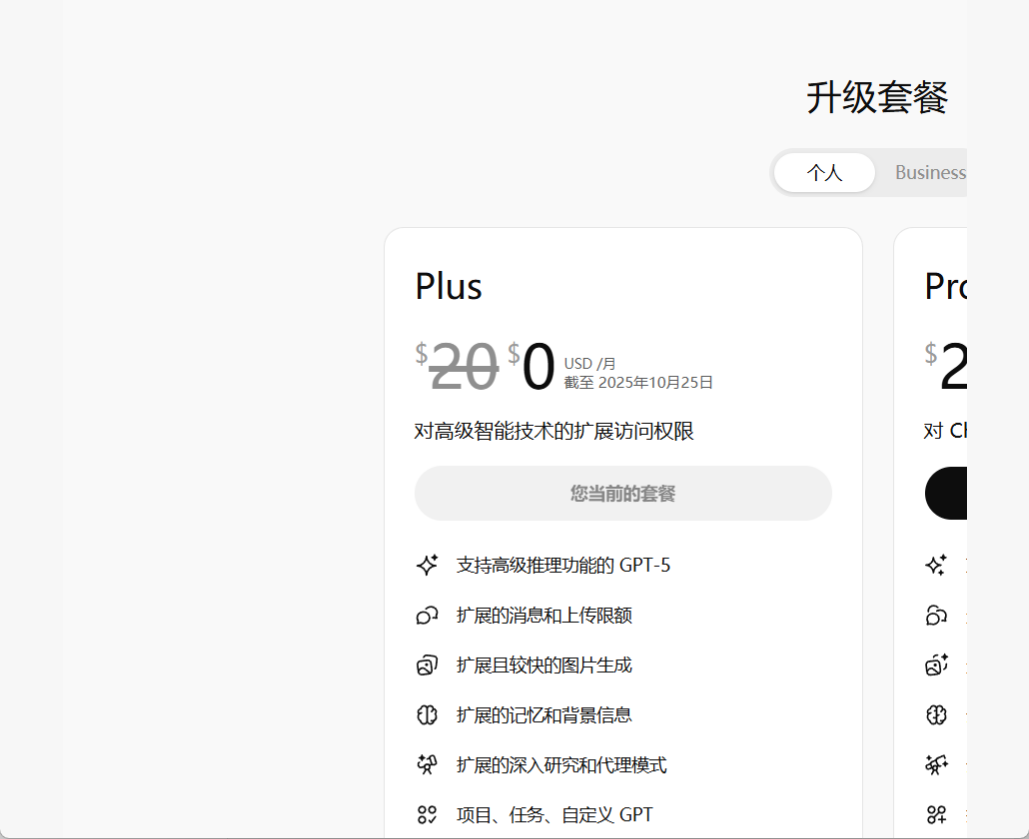
白嫖党狂喜!GPT Plus / Business 免费试用 1 个月来啦!很多人想体验 GPT Plus,却一直舍不得开会员。现在机会来了! 官方放福利:GPT Plus 和 Business 会员限时免费试用一个月! Plus:更快更强,写论文、写代码效率直接翻倍。 Bu...资讯# GPT Plus9个月前06450
Qwen3-TTS – 阿里通义开源的系列语音生成模型,实现精准的语音表达Qwen3-TTS是通义实验室推出的开源语音合成系列模型,集音色复刻、音色定制与精细化语音调控能力于一体,支持客户端实时输入文本并持续接收语音流。模型覆盖10种主流语言(中文、英文、日语、韩语、德语...发现资讯4个月前06440
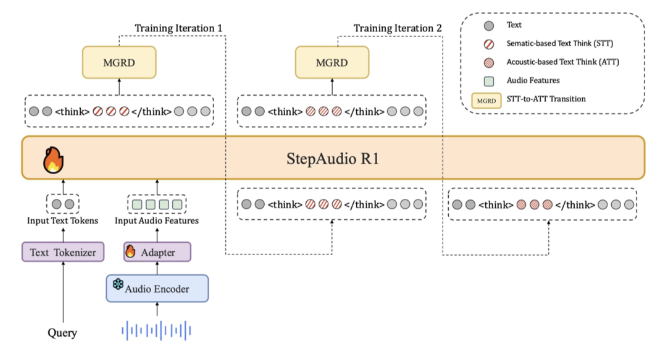
StepAudio R1 – 阶跃星辰推出的全球首个开源原生音频推理模型,真正实现深度推理。StepAudio R1 是阶跃星辰团队推出的全球首个开源原生音频推理模型。模型通过创新的模态锚定推理蒸馏(MGRD)框架,解决了传统音频模型在复杂推理中性能下降的问题,真正实现基于声学特征的深度推理...发现资讯6个月前06400
FLUX.2 – Black Forest Labs开源的AI图像生成与编辑模型,支持同时参考多达10张图片视觉智能实验室 Black Forest Labs 推出了其新一代图像生成模型 FLUX.2,该模型专为实际创作工作流程设计。该模型在细节生成、风格一致性、文本渲染和复杂指令遵循方面均有显著提升。模...资讯6个月前06350
JoySafety – 京东开源的大模型安全框架,支持通过 API 动态调整安全策略京东正式推出了其开源的大模型安全框架 ——JoySafety。框架支持每日超过亿次的调用,拥有高达95% 以上的攻击拦截率,确保用户在享受高效服务的同时,数据安全和用户隐私也得到了有力保障。 JoyS...发现资讯8个月前06330
ViMax – 港大开源的多智能体视频生成框架,导演、编剧、制片人和视频生成器ViMax 是一个多智能体视频生成框架,支持自动化多镜头视频生成,并确保角色与场景的一致性。该框架集导演、编剧、制片人和视频生成器功能于一体,支持多种模式生成分钟级长视频,保持人物与场景一致性。ViM...资讯6个月前06320
微软推出的首款自研图像生成式AI模型–MAI-Image-1 ,能处理复杂的图像生成任务微软正式发布了其首款自主研发的图像生成 AI 模型 ——MAI-Image-1。这一创新模型不仅在生成逼真图像方面表现优异,还能模拟自然光照效果,为用户带来更为生动的视觉体验。该模型在保证生成质量的同...发现资讯8个月前06310