FLM-Audio – 智源研究院开源的全双工音频对话模型,支持本地部署与二次开发flm-audio 是由北京智源人工智能研究院联合 spin matrix 与新加坡南洋理工大学共同推出的原生全双工音频对话大模型,支持中文和英文双语交互。该模型采用创新的原生全双工架构,能够在每一个...发现资讯8个月前06780
Wan-Move – 阿里联合清华等开源的运动可控视频生成框架,满足高质量视频创作需求Wan-Move是由阿里巴巴通义实验室等多机构联合开源的运动可控视频生成框架。该框架以独特的潜在轨迹引导技术为基础,成功实现了视频运动的高质量控制。该框架能够生成长达5秒、分辨率为480p的视频,并且...发现资讯6个月前06770
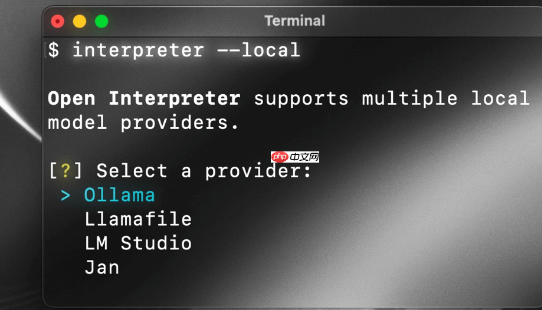
Open Interpreter – 开源AI终端助手,支持在本地环境中运行open interpreter 是一个开源的 ai 终端助手项目,旨在为大型语言模型(llm)赋予本地代码执行能力。通过自然语言交互界面,用户可以通过类似 ChatGPT 的方式在终端中与模型对话...发现资讯4个月前06750
GPT Image 1.5 – OpenAI最新推出的图像生成模型,指令精准修改图像GPT-image-1.5 是 OpenAI 的最新前沿图像生成模型。 它改进了性能、质量、编辑控制和面部保存。能够更好地遵循指令、以特定方式编辑照片,并且生成结果的速度比之前的图像生成模型提升了四倍...发现资讯6个月前06750
FlowithOS – Flowith推出的全球首个智能体操作系统,自动执行复杂任务flowithOS 是全球首个为 Agent 原生设计的智能体操作系统,可以根据用户们发出的任务指令,进行多网页搜索,通过“代码+视觉”的方式来理解用户屏幕画面,并进行自主地思考与执行,完成各种操作...发现资讯7个月前06750
FS-DFM – 苹果联合俄亥俄州立大学推出的扩散语言模型,速度提升128倍苹果提出 FS-DFM 扩散模型,仅需 8 轮快速迭代,即可生成与传统模型上千轮迭代质量相媲美的文本,且写入速度比同类模型最多可提高 128 倍。FS-DFM 在扩散模型的基础上进行了进一步简化,目标...发现资讯8个月前06750
豆包大模型1.6-vision – 火山引擎推出的视觉深度思考模型,具备工具调用能力火山引擎宣布正式推出豆包大模型 1.6-vision,以工具调用的差异化能力,将图像融入其思维链中,实现对图片的定位、剪裁、点选、画线、缩放、旋转等精细处理。在增强推理可解释性的同时,可高效精准地完成...发现资讯8个月前06730
Voquill – 开源AI语音输入工具,语音输入速度是键盘输入的四倍voquill是一款开源语音输入工具,旨在以语音替代传统键盘输入,可在任何文本框和应用程序中使用,实现系统级的通用兼容性。显著提升写作与信息记录的效率,并利用 AI 自动清理转录内容。定位为一个比打字...发现资讯5个月前06710
Vidyard – AI营销视频生成平台,快速生成个性化视频与精准推送Vidyard是一款基于云的视频制作和管理平台,提供丰富的视频编辑和分析工具。内置了专为营销团队设计的转录分析工具。其核心价值在于将转写功能与观众行为分析结合,支持多语言识别,能自动生成可编辑的字幕轨...发现资讯6个月前06690
Depth Anything 3 – 字节跳动推出的视觉空间重建模型,可重建完整3D场景自字节跳动(ByteDance Seed)的研究团队推出—Depth Anything 3 (DA3)视觉空间重建模型,旨在打破3D视觉任务之间的壁垒,实现一个“大一统”的视觉几何模型。DA3的核心思...发现资讯6个月前06690