FlowithOS – Flowith推出的全球首个智能体操作系统,自动执行复杂任务flowithOS 是全球首个为 Agent 原生设计的智能体操作系统,可以根据用户们发出的任务指令,进行多网页搜索,通过“代码+视觉”的方式来理解用户屏幕画面,并进行自主地思考与执行,完成各种操作...发现资讯8个月前06790
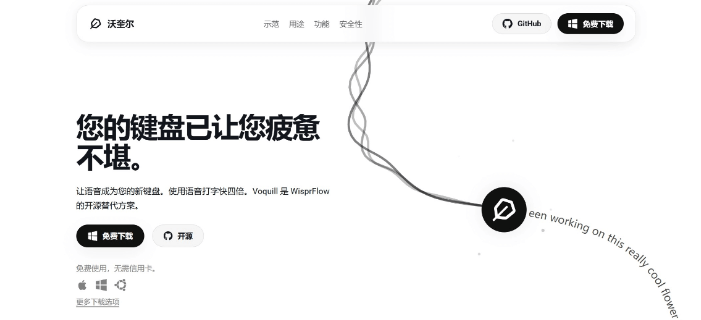
Voquill – 开源AI语音输入工具,语音输入速度是键盘输入的四倍voquill是一款开源语音输入工具,旨在以语音替代传统键盘输入,可在任何文本框和应用程序中使用,实现系统级的通用兼容性。显著提升写作与信息记录的效率,并利用 AI 自动清理转录内容。定位为一个比打字...发现资讯6个月前06780
Depth Anything 3 – 字节跳动推出的视觉空间重建模型,可重建完整3D场景自字节跳动(ByteDance Seed)的研究团队推出—Depth Anything 3 (DA3)视觉空间重建模型,旨在打破3D视觉任务之间的壁垒,实现一个“大一统”的视觉几何模型。DA3的核心思...发现资讯7个月前06770
FS-DFM – 苹果联合俄亥俄州立大学推出的扩散语言模型,速度提升128倍苹果提出 FS-DFM 扩散模型,仅需 8 轮快速迭代,即可生成与传统模型上千轮迭代质量相媲美的文本,且写入速度比同类模型最多可提高 128 倍。FS-DFM 在扩散模型的基础上进行了进一步简化,目标...发现资讯8个月前06770
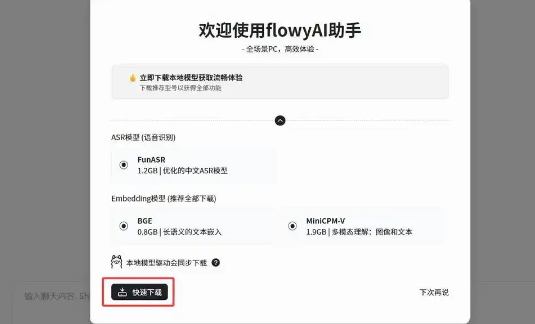
FlowyAIPC – 本地AI办公助手工具,支持多种语言的即时翻译FlowyAIPC 是 Flowy AI 公司推出的面向智能办公领域的 AI 助手产品,这款工具能在完全离线状态下运行,所有数据、聊天记录、知识库内容都保存在本地电脑中,保证了数据的安全性和私密性。它...发现资讯6个月前06760
豆包大模型1.6-vision – 火山引擎推出的视觉深度思考模型,具备工具调用能力火山引擎宣布正式推出豆包大模型 1.6-vision,以工具调用的差异化能力,将图像融入其思维链中,实现对图片的定位、剪裁、点选、画线、缩放、旋转等精细处理。在增强推理可解释性的同时,可高效精准地完成...发现资讯9个月前06760
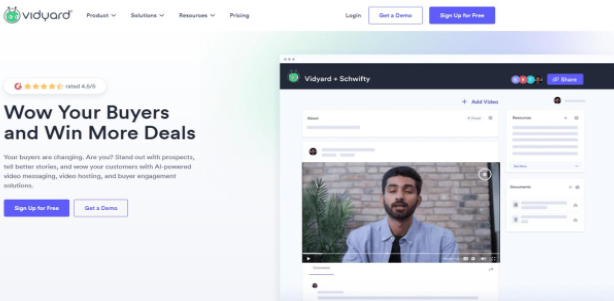
Vidyard – AI营销视频生成平台,快速生成个性化视频与精准推送Vidyard是一款基于云的视频制作和管理平台,提供丰富的视频编辑和分析工具。内置了专为营销团队设计的转录分析工具。其核心价值在于将转写功能与观众行为分析结合,支持多语言识别,能自动生成可编辑的字幕轨...发现资讯7个月前06730
Seedance 1.0 lite – 火山引擎推出的视频生成模型,支持文生视频和图生视频Seedance 1.0 lite是火山引擎推出的豆包视频生成模型的小参数量版本,支持文生视频和图生视频两种生成方式,支持生成5秒或10秒、480p或720p分辨率的视频。支持360度环绕、航拍、变焦...发现资讯6个月前06720
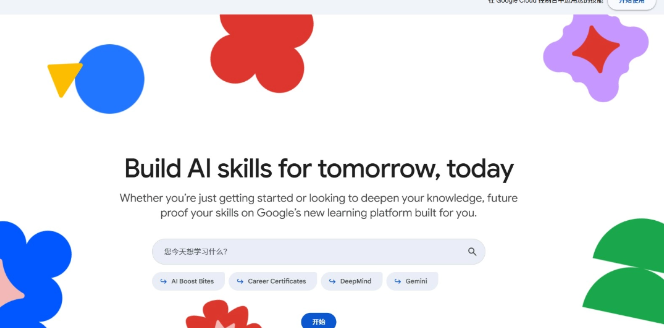
Google Skills – 谷歌推出的AI技能学习平台,支持真实代码编写和实时反馈,Google 近日推出了一个名为“Google Skills”的全新学习平台,旨在帮助用户掌握数字时代所需的核心技能。致力于弥合 AI 领域的技能鸿沟。Google Skills 平台致力于培养具备实...发现资讯8个月前06710
Hunyuan-MT-7B – 腾讯开源的轻量级翻译模型,能快速准确地完成翻译任务Hunyuan-MT-7B是什么 Hunyuan-MT-7B 是腾讯混元发布的轻量级翻译模型,参数量为70亿,支持33个语种及5种民汉语言/方言的互译,包括粤语、维吾尔语、藏语等。模型采用完整的训练范...发现资讯11个月前06700